The initial phase of generative AI experimentation is officially over. The strategic mandate has shifted from building rapid proofs-of-concept to managing long-term production margins. When evaluating whether to build or buy enterprise AI infrastructure, relying purely on the advertised vendor pricing of cost per one thousand tokens is a common trap. Token costs are highly volatile variables that fail to reflect the multi-year architectural realities of enterprise platforms.
A true infrastructure evaluation requires a comprehensive 3-year runway model. This timeframe aligns directly with standard corporate hardware depreciation cycles, engineering retention timelines, and cloud contract commitments.
The core architectural debate pits full data pipelines and infrastructure control against hyperscaler agility. On one side, open-weight frameworks allow engineering teams to host proprietary architectures. On the other hand, managed ecosystems offer turnkey deployment velocity. While serverless hyperscaler APIs excel at accelerating early MVP rollouts, a rigorous private LLM TCO analysis reveals a stark reality.
As application adoption scales into millions of daily production queries, linear token pricing transforms into an unsustainable infrastructure tax. This reality makes self-hosted, dedicated open-weights environments the optimal destination for long-term enterprise efficiency.
Decoding the True Variables of Private LLM TCO
Calculating the economic profile of a self-hosted, open-weights model requires looking far beyond the initial infrastructure deployment. To accurately forecast a private LLM TCO, engineering leaders must account for a complex mix of recurring capital expenditures and specialized operational costs.
Hardware Acquisition and Infrastructure Constraints
The baseline foundation of any private AI deployment is high-performance compute availability. Organizations must weigh the financial implications of committing to 3-year cloud reserved instances (such as AWS EC2 P5 instances or Azure NDv5 virtual machines) against utilizing specialized bare-metal GPU clouds or deploying on-premises hardware.
PRIVATE LLM COMPUTE OPTIMIZATION
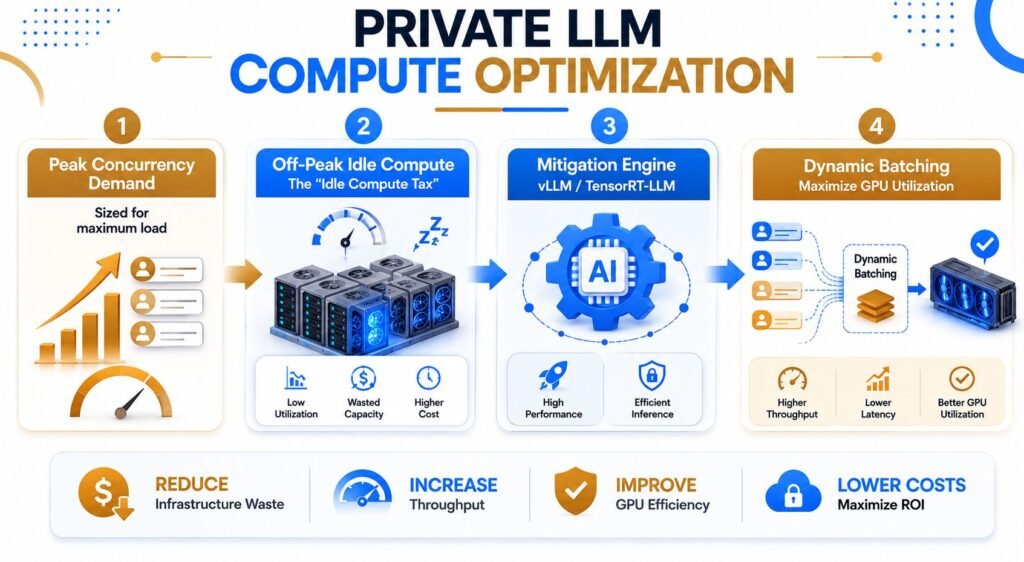 A major operational variable here is the idle compute tax. Unlike serverless setups, dedicated GPU clusters incur costs whether they are actively processing data or sitting idle. If your cluster is underutilized during off-peak corporate hours, your actual cost per inference rises significantly unless your platform team implements dynamic cluster resizing or schedules background batch-processing jobs.
A major operational variable here is the idle compute tax. Unlike serverless setups, dedicated GPU clusters incur costs whether they are actively processing data or sitting idle. If your cluster is underutilized during off-peak corporate hours, your actual cost per inference rises significantly unless your platform team implements dynamic cluster resizing or schedules background batch-processing jobs.
Engineering Overhead and Talent Retention
Deploying open-weights models like Llama 3 or Mistral requires highly specialized human capital. To maintain a private inference stack, a platform must support the fully burdened salaries of dedicated MLOps, infrastructure, and data security engineers.
These teams do not simply manage servers; they write custom quantization scripts, configure distributed inference engines, and optimize memory allocations to extract maximum throughput from every gigabyte of VRAM.
Finetuning, Alignment, and Data Pipeline Maintenance
A static model degrades in corporate utility over time. Maintaining competitive performance requires ongoing investments in Parameter-Efficient Fine-Tuning (PEFT) frameworks, such as LoRA or QLoRA. This necessitates continuous data engineering pipelines to clean and curate enterprise training data.
Additionally, organizations must fund the underlying retrieval-augmented generation (RAG) infrastructure, including production-grade vector database hosting, continuous document embedding recalculations, and semantic search optimizations.
The Hidden Cold-Start and Architectural Tail Risks of Private Clusters
While the economic advantages of private infrastructure scale impressively with volume, a transparent private LLM TCO projection must account for systemic operational risks.
Model Obsolescence and Hardware Lock-in
Locking your enterprise into a rigid 3-year compute lease creates a distinct hardware depreciation risk. The rapid pace of algorithmic innovation means that a massive parameter model requiring multi-GPU nodes today might be outperformed tomorrow by a highly quantized, smaller model requiring half the hardware footprint. If your team signs a restrictive cloud reservation contract based on current performance parameters, you risk paying a premium for stranded, suboptimal hardware resources if architectural requirements suddenly shift.
High Availability and Disaster Recovery Multipliers
Matching the strong uptime SLAs provided natively by global hyperscalers requires redundant infrastructure. Platform architects must design multi-region failover pipelines, deploy load balancers across disparate data centers, and maintain active-active hot standby clusters. This duplicate infrastructure setup effectively doubles your baseline compute costs until your traffic scale is large enough to naturally saturate multiple geographic hubs.
The Hyperscaler Alternative: AWS Bedrock TCO Comparison
Amazon Web Services addresses enterprise AI through a serverless, modular architecture. Evaluating an AWS Bedrock TCO comparison requires understanding the financial trade-offs between rapid deployment and long-term variable expenses.
Understanding Bedrock’s Pricing Structure
Amazon Bedrock divides its financial commitments into two distinct consumption models:
- On-Demand: A strict pay-as-you-go framework billed directly on the volume of input and output tokens processed. This structure features zero upfront capital investments, making it highly economical for unpredictable or low-volume application traffic.
- Provisioned Throughput: Designed for consistent, production-grade applications requiring strict latency guarantees. This model requires a time-based commitment (typically 1-month or 1-year terms) to reserve dedicated model slots, transforming your variable API costs into a predictable, fixed operating expense.
The Hidden Costs of the AWS Ecosystem
While the headline token costs remain transparent, integrating Bedrock into a production-grade enterprise platform introduces several indirect cloud expenses. High-throughput applications generate massive volumes of interaction logs, which rapidly increase AWS CloudWatch storage costs.
Furthermore, routing enterprise data out of corporate storage buckets into serverless model environments incurs ongoing data transit and processing fees. When you add the cost of running supporting components like Amazon OpenSearch Serverless for vector indexing and AWS KMS for enterprise-grade encryption key management, the supplementary infrastructure fees can increase your base AI compute bill by a significant margin.
The Enterprise Challenger: Azure OpenAI Cost Analysis
Microsoft Azure positions its OpenAI service as a highly secure option for corporate deployments. Conducting an enterprise AI cost analysis within this ecosystem requires a careful evaluation of how enterprise compliance fees compound over time.
Pay-As-You-Go vs Provisioned Throughput Units (PTUs)
Similar to AWS, Azure offers token-based consumption alongside its Provisioned Throughput Units (PTUs) framework. PTUs grant dedicated, consistent throughput capacity for specific models like GPT-4o.
However, securing PTU slots requires explicit contractual commitments. If your actual application traffic falls short of your allocated PTU threshold, your organization is still legally responsible for the entire reservation fee. This dynamic significantly inflates your actual cost per token.
Conversely, if your application traffic exceeds your contracted PTU limits, your system will throttle user requests or fallback to unreserved lines, degrading performance unless you purchase expensive overage buffers.
The Cost of Global Redundancy and Compliance
For enterprises operating in heavily regulated industries like financial services or healthcare, standard serverless endpoints are rarely sufficient. Meeting strict data privacy requirements means integrating Azure Private Links to keep traffic completely isolated from the public internet.
Configuring localized data residency boundaries to comply with geographic mandates, along with deploying advanced data logging filters, introduces supplementary platform premiums. These security and compliance overhead costs add up quickly, significantly increasing the net operating cost of the underlying model.
The 3-Year Compounding Premium
Over a 36-month timeline, Azure’s pricing model can lead to significant cost inflation for high-volume enterprise users. While Microsoft provides deep enterprise-wide software discounts, these multi-year commitments lock platforms into proprietary API ecosystems. This lock-in limits your ability to migrate workloads to more cost-effective alternative models as open-source alternatives advance.
3-Year Cost Simulation Matrix
To illustrate how these variables interact over time, this model evaluates a high-volume enterprise deployment scaling from a Year 1 pilot phase to full Year 3 production operations, averaging 50 million monthly requests by maturity.
Year 1 to Year 3 Trajectory Dynamics
- Year 1 (Implementation Phase): Hyperscaler models consistently deliver lower overall costs. Capital expenditure is minimal, and teams can deploy applications without hiring specialized infrastructure engineers.
- Year 2 (The Scale Inflection): As application adoption grows across enterprise departments, monthly API usage climbs. This causes hyperscaler token fees to rise linearly, matching the fixed operational and staffing costs of a private cluster.
- Year 3 (Amortized Optimization): The financial dynamics invert. The initial setup and development costs of the private LLM infrastructure have amortized, and labor costs stabilize. Meanwhile, the hyperscaler approach continues to incur compounding, linear consumption fees.
3-Year TCO Comparison Matrix
The table below illustrates how the different cost centers distribute over a 36-month horizon for a high-volume enterprise deployment:
| Cost Center Component | Private LLM Stack (Self-Hosted) | AWS Bedrock Ecosystem | Azure OpenAI Service |
|---|---|---|---|
| Year 1 Capital / Token Outlay | High (Upfront clusters & data pipelines) | Low (Pay-as-you-go token volumes) | Low (Baseline consumption fees) |
| Year 3 Capital / Token Outlay | Minimal (Amortized hardware maintenance) | Extreme (Linear token accumulation) | Extreme (High PTU subscription renewals) |
| Engineering & MLOps Labor | High (Dedicated infrastructure engineers) | Low (Generalist cloud software teams) | Low (Standard platform administrators) |
| Ecosystem Data & Logging Fees | Included in base cluster compute | High (CloudWatch & OpenSearch fees) | High (Private Link & Sentinel tracking) |
| Compliance & Isolation Surcharges | Included (Native structural isolation) | Medium (Provisioned isolation costs) | High (Regulated geography boundaries) |
| 3-Year Cumulative Cost Profile | Predictable, Step-Wise Scalability | Volatile, Consumption-Driven | Compounding, Vendor-Locked |
Strategic Trade-Offs Beyond the Financial Ledger
While raw financial metrics are critical, the final choice between custom infrastructure and managed APIs depends on broader platform strategy considerations.
Data Privacy, Security, and IP Sovereignty
For enterprises operating in highly regulated fields, the risk of data exposure presents a significant financial liability. Transitioning to a private infrastructure design ensures that sensitive client interactions and proprietary corporate data sets remain completely enclosed within your corporate firewall. This setup eliminates the risk of data leakage or unauthorized model training usage by third-party API providers.
Vendor Lock-in vs Architectural Agility
Relying entirely on a closed-source ecosystem limits your platform’s long-term flexibility. If a vendor changes its API structure, modifies its model alignment rules, or alters its pricing tiers, your entire enterprise platform must adapt.
Adopting a private infrastructure strategy built on open-weight foundation models gives your platform team full ownership of the technology stack. This architecture allows you to easily swap models, adjust quantization levels, and migrate across cloud providers as open-source innovations evolve.
Conclusion
The 3-year financial model demonstrates that for scale-focused enterprise operations, migrating toward a managed-private deployment is a strategic necessity for protecting corporate operational margins. Managed hyperscaler services remain an excellent option for fast-paced prototyping and low-volume applications. However, relying on them for large-scale, core production systems can lead to volatile, unpredictable infrastructure bills that scale linearly with your success.
Don’t let variable token costs disrupt your product infrastructure budgets. Stop guessing your long-term cloud expenditure.
FAQs
Q1: What are the hidden infrastructure expenses in a private LLM TCO?
A: Beyond hardware leases, hidden expenses include multi-region failover architecture, high-volume vector database hosting, specialized MLOps engineering labor, continuous data egress fees, and ongoing custom corporate training data pipeline maintenance.
Q2: How does a private LLM vs Bedrock cost comparison scale with high user traffic?
A: AWS Bedrock scales linearly on token consumption, which can create volatile budgets at high volumes. Conversely, private LLMs absorb massive scaling traffic smoothly because operational costs remain capped by your hardware footprint.
Q3: When should a platform leader choose an AWS Bedrock TCO comparison over Azure OpenAI?
A: Prioritize Bedrock when deep integration with existing AWS data pipelines is vital. Choose Azure OpenAI if your corporate ecosystem dictates strict reliance on Microsoft’s enterprise compliance and existing licensing agreements.
Q4: Can an enterprise AI cost analysis justify a hybrid infrastructure deployment model?
A: Absolutely. Enterprises frequently use Azure OpenAI or AWS Bedrock for fast prototyping and low-volume features, while offloading mature, high-volume core workflows to a self-hosted private LLM to optimize margins.