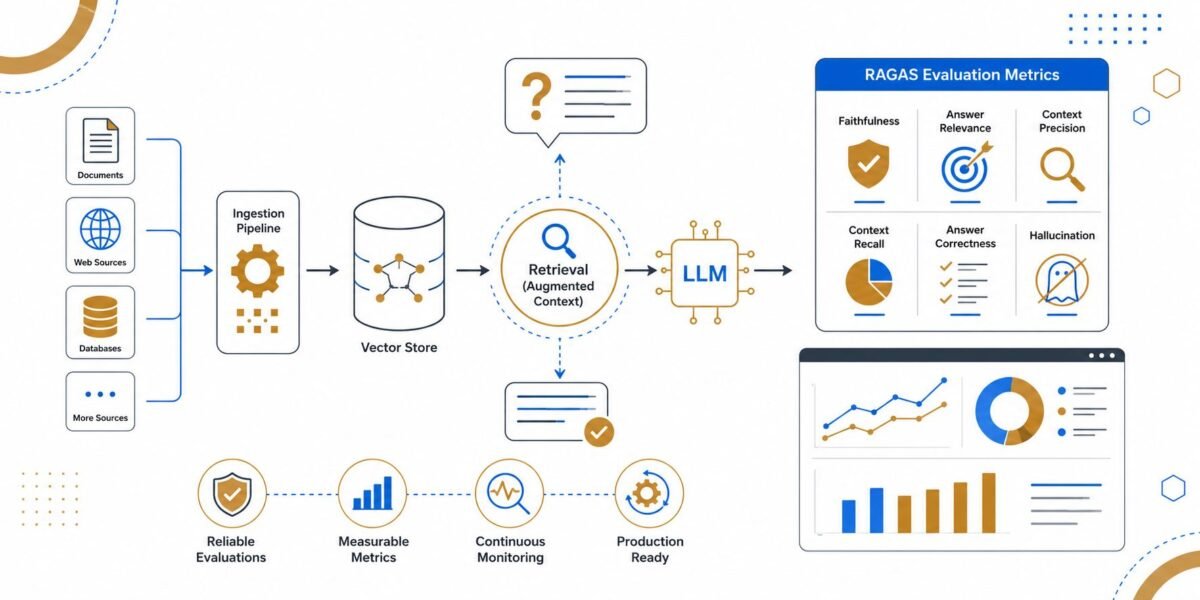
If you’ve deployed a retrieval-augmented generation (RAG) system, you know the pain: answers look great in a demo but hallucinate or drift once live. That’s why RAGAS evaluation production is no longer optional, it’s the backbone of trustworthy AI.
This guide shows you how to design, test, and monitor production-grade RAG systems using a practical RAG evaluation framework, rigorous LLM faithfulness testing, and proven RAGAS implementation patterns. Along the way, you’ll see how platforms like AIVeda help teams move faster with less risk.
What is RAGAS Evaluation Production and Why It Matters
RAGAS evaluation production means running RAG evaluation continuously in real environments, not just offline benchmarks. It covers accuracy, faithfulness, latency, cost, and compliance for every user query. The goal is to catch failures before users notice them.
Business and technical drivers
Product teams care because hallucinations erode trust, trigger compliance risks, and increase support costs. A solid evaluation strategy ties directly to ROI: fewer escalations, higher retention, and faster iteration cycles.
Common failure modes in production
Typical issues include:
- Hallucinated citations or invented facts
- Stale or irrelevant retrieved passages
- Retrieval noise at scale
- Latency spikes under load
These failures are predictable if you measure them early and often. This is why RAGAS evaluation production is essential for any serious ML team.
A Practical RAG Evaluation Framework for Production-Grade Systems
A production-ready RAG evaluation framework has four stages: offline benchmarks, synthetic scenario tests, shadow or canary deployments, and continuous live monitoring. Each stage adds realism and reduces risk before full rollout. Offline benchmarks let you compare versions on a fixed dataset, while synthetic tests explore edge cases that rarely appear in real data.
Shadow and canary deployments let you see how the system behaves with real traffic but without affecting all users. Continuous monitoring then closes the loop by tracking quality over time and alerting when SLOs are breached. This layered approach is far more robust than relying on a single type of test.
Key metrics to track
Track these core signals:
- Relevance: Does the answer match the query intent?
- Faithfulness: Is the answer grounded in retrieved evidence?
- Retrieval precision/recall: Are the right documents fetched?
- Latency & cost: Can you meet SLOs at scale?
Faithfulness is especially critical; this is where LLM faithfulness testing becomes a must-have.
Designing experiments and baselines
Control variables like:
- Query distribution
- Knowledge base version
- Retriever configuration
Use baselines to measure improvement from new index strategies, hybrid retrieval, or model upgrades.
How this framework maps to production pipelines
Embed evaluation into CI/CD: run offline tests on every commit, trigger shadow tests on staging, and enforce rollback if SLOs degrade. This operationalizes your RAG evaluation framework and makes quality part of the deployment pipeline. Evaluation stops being a separate phase and becomes a gate that every change must pass through.
When evaluation is automated, engineers get fast feedback instead of waiting for manual reviews. This accelerates iteration while reducing the risk of shipping regressions. Over time, the system becomes more robust because every change is validated against the same standards.
LLM Faithfulness Testing and Practical Steps for Reliable Evaluation
What is LLM faithfulness testing and its importance
LLM faithfulness testing checks whether an answer is fully supported by retrieved evidence. Low faithfulness means the model is hallucinating or inventing facts. In production, this directly impacts trust and compliance.
Test types: unit, scenario-driven, adversarial
Use layered tests:
- Unit tests: fixed queries with known ground truth
- Scenario tests: multi-hop, ambiguous, or time-sensitive queries
- Adversarial tests: red-team prompts designed to trigger hallucinations
This mix exposes weaknesses offline before users do.
Automated vs human-in-the-loop validation
Automated tests scale but miss nuance. Human review catches edge cases, regulatory concerns, and subtle faithfulness failures. A hybrid approach is ideal:
- 90% automated coverage
- 10% targeted human review on high-risk queries
This balance is key for sustainable RAGAS evaluation production.
Tooling recommendations
Look for:
- Provenance tracing (which document supports which claim)
- Explainability probes (why did the model pick this answer?)
- Logging and replay for incident investigation
Tools that support LLM faithfulness testing should export metrics into dashboards and alerting systems.
RAGAS Implementation Patterns for Scalable, Maintainable Deployments
Architectural patterns
Common patterns include:
- Retriever-first: optimize retrieval before tuning the LLM
- Hybrid retrieval: combine dense embeddings with sparse keyword search
- Dual-encoder vs cross-encoder: trade latency for precision
Your architecture shapes what RAGAS implementation choices are feasible.
Integrating evaluation into the ML lifecycle
Embed evaluation at every stage: pre-deploy gates, canary mode, and shadow mode. No rollout should happen if faithfulness drops below the SLO. Canary mode routes a small percentage of traffic to the new version while monitoring metrics. Shadow mode compares old and new versions without affecting users.
This ensures RAGAS evaluation production is part of the lifecycle, not an afterthought. Evaluation becomes a gate that every change must pass before reaching production users. Over time, this discipline reduces the frequency and severity of quality incidents.
Data and index management best practices
- Keep corpora fresh with incremental indexing
- Segment by domain, time, or sensitivity
- Version indexes and track changes
Stale data is a top cause of retrieval decay in production.
Security, privacy, and compliance considerations
Mask PII before indexing or evaluation, enforce access controls on knowledge stores, and audit all evaluation runs for compliance. These practices are non-negotiable for enterprise deployments. A RAG system that leaks sensitive data is a liability, no matter how accurate its answers.
Security and privacy also affect how you design evaluation. You may need to anonymize logs, restrict access to metrics, or run evaluation in isolated environments. Compliance requirements may dictate how long you keep logs and who can access them.
Production Monitoring, Alerting, and Continuous Improvement
Monitoring signals to prioritize
Watch for:
- Drift in faithfulness or relevance scores
- Retrieval precision decay over time
- Cost-per-query spikes
- Latency p95/p99 increases
These are early warnings that your RAG system is degrading.
Alerting and SLOs
Define SLOs like:
- Faithfulness ≥ 90%
- Relevance ≥ 85%
- p95 latency ≤ 2s
Set alerts when metrics breach thresholds for sustained periods. Automate rollback or traffic throttling when needed.
Feedback loops for iterative improvement
Ingest user feedback such as thumbs up/down and corrections, build label pipelines for hard cases, and trigger retraining or index refresh automatically. This closes the loop and makes RAGAS evaluation production truly continuous. Feedback from real users is the most valuable signal you can have.
Label pipelines let you turn user feedback into training data or evaluation sets. Automated triggers ensure that improvements happen without manual intervention. Over time, the system becomes self-correcting, with evaluation and feedback driving continuous improvement.
Example playbook for an incident
- Detect: monitoring flags faithfulness drop
- Isolate: shift traffic to shadow or rollback
- Fix: adjust retrieval, prompt, or index
- Validate: re-run tests and SLO checks
- Deploy: gradual rollout with monitoring
Having this playbook is a hallmark of mature RAGAS evaluation production. It turns a crisis into a routine process. Teams that practice this playbook respond faster and recover more cleanly when issues arise.
How AIVeda Accelerates Production-Grade RAGAS Evaluation
AIVeda offers an end-to-end platform for automated RAG evaluation framework setup, built-in LLM faithfulness testing with provenance tracing, real-time monitoring dashboards and alerting, and CI/CD integrations for seamless deployment. This reduces the engineering overhead of RAGAS evaluation production.
Instead of building evaluation infrastructure from scratch, teams can leverage AIVeda’s pre-built components. This accelerates time-to-value and ensures best practices are baked in from the start. The platform is designed for ML engineers who want to focus on model quality.
Contact us to see how we can help you ship trustworthy AI faster
Step-By-Step Checklist: From Prototype to Production-Ready RAGAS Evaluation Production
Pre-launch checklist
- Define SLOs for faithfulness, relevance, latency
- Prepare benchmark datasets and synthetic tests
- Set up baseline metrics and logging
- Review security and privacy controls
Launch checklist
- Run canary or shadow deployment
- Enable real-time monitoring and alerting
- Capture user feedback mechanisms
- Document rollback procedures
Post-launch checklist
After launch, schedule continuous evaluation cadence daily or weekly, set up retraining or index refresh triggers, review SLO compliance and cost trends, and iterate on prompts, retrieval, and evaluation rules. This phase ensures your system continues to improve over time.
Continuous evaluation catches degradation before users notice. Retaining triggers ensures your model and index stay fresh. SLO reviews keep you aligned with business goals. Iteration on prompts and retrieval ensures the system adapts to changing needs.
Example timeline (8-12 week pilot)
- Weeks 1-2: Define SLOs, prepare datasets, baseline metrics
- Weeks 3-4: Implement offline tests and LLM faithfulness testing
- Weeks 5-6: Shadow deployment, monitor, tune
- Weeks 7-8: Canary rollout, finalize monitoring, document playbook
- Weeks 9-12: Full rollout, continuous improvement, scale
This structured approach is a practical expression of RAGAS evaluation production.
Conclusion
Building trustworthy RAG systems isn’t about a one-time test; it’s about RAGAS evaluation production continuous, measurable, and integrated into your ML lifecycle. With a solid RAG evaluation framework, rigorous LLM faithfulness testing, and pragmatic RAGAS implementation, you can reduce hallucinations, meet SLOs, and ship with confidence.
If you want to accelerate this journey, AIVeda can help you set up evaluation, monitoring, and CI/CD gates faster. Request a demo or download the pilot checklist to start your production-grade RAG evaluation today.
FAQs
Q1: What differentiates RAGAS evaluation production from basic RAG testing?
A: RAGAS evaluation production focuses on continuous, real-user validation with SLOs, monitoring, and CI/CD integration, not just offline benchmarks.
Q2: How do I measure LLM faithfulness reliably?
A: Combine automated provenance checks, adversarial prompts, and targeted human reviews to quantify hallucination rates and evidence alignment for solid LLM faithfulness testing.
Q3: When should I use human-in-the-loop versus automated checks?
A: Use automated checks for scale and coverage; apply human review for high-risk queries, regulatory needs, and nuanced faithfulness failures in RAGAS evaluation production.
Q4: Can AIVeda plug into existing retrievers and knowledge stores?
A: Yes. AIVeda supports common retrievers and vector stores, running alongside existing pipelines with minimal disruption for easier RAGAS implementation.
Q5: What’s a realistic timeline for productionizing RAGAS evaluation?
A: An 8-12 week pilot can deliver deployable monitoring and baseline metrics; wider rollouts depend on corpus size, integrations, and team capacity.