Enterprises today are no longer asking if they should adopt generative AI — they are asking how to adopt it safely and strategically. Large Language Models (LLMs) are powering everything from intelligent agents and search to knowledge management and automated documentation. But for many organizations — particularly in healthcare, banking, pharma, defense and manufacturing — sending sensitive data to public LLM APIs simply isn’t acceptable.
That’s where private LLMs development becomes mission-critical. Developing and deploying LLMs inside your controlled environment (on-premise or private cloud) enables enterprises to keep data and IP inside the firewall, comply with regulatory obligations, and fine-tune models on proprietary datasets to deliver domain-specific intelligence.
In this guide we cover the full lifecycle of private LLMs development: definitions and business case, architecture and infrastructure, data and governance, deployment options, industry use cases, cost models, risks and mitigations, best practices, and future trends. We’ll also discuss how to integrate private LLMs with enterprise systems and how to evaluate vendors and partners as part of a demand-generation and go-to-market motion.
We write this guide for CIOs, CTOs, Heads of AI, CISOs, Chief Data Officers, and product leaders who are sponsoring or evaluating private LLM programs. Throughout, we emphasize practical advice you can apply today and highlight the commercial, operational, and regulatory factors that drive enterprise adoption.
What Are Private LLMs?
Private LLMs are large language models that are developed, fine-tuned, hosted, and served within an organization’s controlled environment — either on-premise, in a dedicated private cloud, or through a hybrid architecture. Unlike public LLM APIs where queries and training data travel to third-party providers, private LLMs keep data and model artifacts inside a governed boundary.
Key characteristics:
- Data sovereignty: Training data, prompt histories, and inference logs remain under enterprise control.
- Customization: Models can be fine-tuned on domain-specific corpora, internal knowledge bases, and proprietary ontologies.
- Governance: Organizations can implement audit trails, RBAC, monitoring, and compliance controls.
- Deployment choice: Options range from fully air-gapped on-prem systems to secure private clouds with controlled ingress/egress.
Private LLMs are not a single product; they are an architectural approach that combines model selection (open-source or licensed), data engineering, MLOps, security controls, and application integration. The objective is to deliver the benefits of LLMs — automation, insights, and productivity — without exposing sensitive assets to external providers.
The Case for Private LLMs Development
Why do enterprises invest in private LLMs? The reasons combine risk mitigation, regulatory compliance, and strategic differentiation:
- Regulatory & legal compliance: Many organizations must meet HIPAA, GDPR, sectoral regulations (RBI/SEBI in India, FINRA in the U.S., etc.), or contractual obligations that require data residency and controlled processing. Private LLMs allow compliance by design.
- Protect intellectual property: R&D, proprietary algorithms, internal documentation, and product plans are competitive assets. Private LLMs keep that IP from being accidentally shared with third parties.
- Control & governance: With private LLMs we can enforce RBAC, logging, explainability policies, and human-in-the-loop review processes — essential for regulated use cases and auditability.
- Customization for domain performance: Off-the-shelf public models often lack industry nuance. Fine-tuning on internal datasets significantly improves accuracy and reduces hallucination risk in specialized domains.
- Predictable economics at scale: For high-volume inference and fine-tuning workloads, private infrastructure can be more cost-effective than large recurring API bills and may provide capacity reuse across teams.
- Trust & customer confidence: Being able to state that models are run within a controlled environment can be a commercial differentiator in enterprise procurement.
In short, private LLMs are about enabling secure, compliant, and business-aligned AI — not merely running models behind a firewall.
Evolution of Private LLMs: From APIs to On-Prem Deployment
Enterprise LLM adoption has gone through distinct phases:
- Experimentation with public APIs: Early pilots used cloud APIs for speed and convenience. This phase proved concept viability but exposed limitations around data control, cost, and customization.
- Private cloud & managed deployments: Enterprises began moving sensitive workloads to private clouds (VPCs, dedicated tenancy) to reduce exposure while retaining scalability.
- On-prem & air-gapped environments: Where regulatory and security requirements are strict, organizations built fully on-prem, air-gapped environments. This enables the highest level of data sovereignty.
- Hybrid operating model: Today, many enterprises adopt a hybrid stance: critical workloads and fine-tuning occur on-prem or in private clouds while non-sensitive, bursty inference may use controlled public cloud resources.
Along the way, improvements in model efficiency (quantization, sparse models), ecosystem maturity (MLOps tooling), and open-source model availability accelerated private LLM feasibility. The net result: enterprises now have robust architectural patterns and vendor options to develop private LLMs at scale.
Key Benefits of Private LLMs Development
Private LLMs bring multiple tangible and strategic benefits. We summarize the key advantages below and explain why each matters.
1. Data Sovereignty and Privacy
Keeping data inside your controlled boundary mitigates legal, contractual, and reputational risks. This is essential for patient records, financial transaction histories, defense data, and regulated supply chain details.
2. Regulatory Compliance
Implementation of compliance controls is easier when data never leaves jurisdictional boundaries. Private deployment enables us to implement region-specific data processing rules, data retention policies, and auditability required by regulators.
3. Customization & Domain Performance
Fine-tuning a model on your own knowledge base — including SOPs, historical tickets, contracts, and domain literature — delivers superior relevance and reduces errors that arise from domain mismatch.
4. Security and Governance
We can implement enterprise-grade controls: encrypted storage, hardware-backed keys, role-based access, SIEM integrations, strict network segmentation, and forensic logging. These are often required for procurement and audits.
5. Predictable and Scalable Economics
Though the upfront CapEx is higher for on-prem infrastructure, predictable capacity management and amortization over multiple projects can reduce total cost of ownership versus pay-per-call APIs, especially at high volumes.
6. Competitive Differentiation
Private LLMs let product and knowledge teams embed proprietary behaviors in AI assistants and workflow automation, creating unique internal capabilities and customer-facing offerings that competitors cannot replicate easily.
7. Operational Independence
We avoid vendor outages or sudden T&Cs changes by retaining control over model hosting. This reduces operational risk for critical enterprise services.
8. Better Integration with Enterprise Systems
Hosting inside the enterprise network simplifies secure integration with ERP/CRM/BI systems and internal databases without needing complex egress policies or data pipelines to external vendors.
Taken together, these benefits make private LLM development not just a technical project but a strategic initiative that touches security, legal, operations, and product strategy.
Core Components of Private LLMs Development
Developing private LLMs requires an orchestration of several technical and organizational components. Below are the core pillars we must design and operate.
1. Model Selection & Architecture
Choose a base model (open-source like LLaMA/Falcon/Mistral or licensed proprietary models) and decide on architecture variants (decoder-only vs encoder-decoder, multi-modal extensions). Evaluate trade-offs in size, latency, and cost.
2. Training & Fine-Tuning Pipelines
Create repeatable pipelines for fine-tuning, parameter-efficient tuning (LoRA, adapters), and supervised/reinforcement objectives. Maintain rigorous version control for weights and checkpoints.
3. Data Engineering
Curate, clean, and label training datasets. Implement ETL processes, data deduplication, and quality checks. Establish pipelines for producing embeddings and building retrieval corpora.
4. Embeddings & Retrieval Systems
Develop robust embedding strategies and vector databases for retrieval-augmented generation (RAG). Embedding quality directly impacts retrieval precision.
5. Inference Infrastructure
Provision GPU clusters, inference optimizations (quantization, batching), and autoscaling for production workloads. Design latency SLAs and monitoring.
6. MLOps & DevOps
Automate CI/CD for models, tests to detect drift and regressions, canary deployments, and rollback mechanisms. Track model lineage and metadata.
7. Security & Compliance Controls
Apply encryption-at-rest and in-transit, HSMs for key management, network isolation, RBAC, and logging. Ensure compliance with applicable standards.
8. Application Integration
Expose secure APIs and connectors to embed LLM capabilities into chatbots, search, knowledge workbenches, and business processes.
A robust private LLM program coordinates these components with clear ownership and governance across teams.
Data Privacy & Governance in Private LLMs
Data governance is the backbone of an enterprise private LLM program. When we develop private models, governance must be baked into every phase of the lifecycle.
Principles of Effective Governance
- Data lineage & provenance: Track where training data originated, who approved it, and how it’s been transformed.
- Least privilege & RBAC: Limit access to models and datasets to only authorized teams and roles.
- Purpose limitation: Define acceptable uses for models and enforce them through policies and technical guards.
- Auditability & logging: Log prompts, responses, and system actions to support incident forensics and compliance reporting.
- Privacy-preserving methods: Use differential privacy, synthetic data, and anonymization where appropriate.
Practical Controls
- Implement segregated data zones for PII, regulated datasets, and general corpora.
- Use vector stores that support encrypted storage for embeddings and enforce access policies at the vector DB layer.
- Maintain a model registry that stores metadata, artifact hashes, training datasets, and evaluation metrics.
- Integrate policy engines to block forbidden prompts (e.g., export-controlled queries) and to flag risky outputs.
Improving Retrieval Safety
Higher quality embeddings and careful chunking of content improve retrieval accuracy and reduce hallucinations. For practical RAG implementations, we recommend following structured chunking and embedding enhancement techniques like the chunking strategy we use for retrieval pipelines. Refer to our guide on improving text embeddings to understand embedding optimization and retrieval combinations.
(Internal reference: improving text embeddings with LLMs — used once.)
Governance Organization
Create a cross-functional AI governance board including representatives from legal, compliance, security, data science, and product management. Document policies and operationalize them through automation and monitoring.
Good governance reduces risk, accelerates approvals, and builds trust across stakeholders.
On-Premise vs Private Cloud Deployment Options
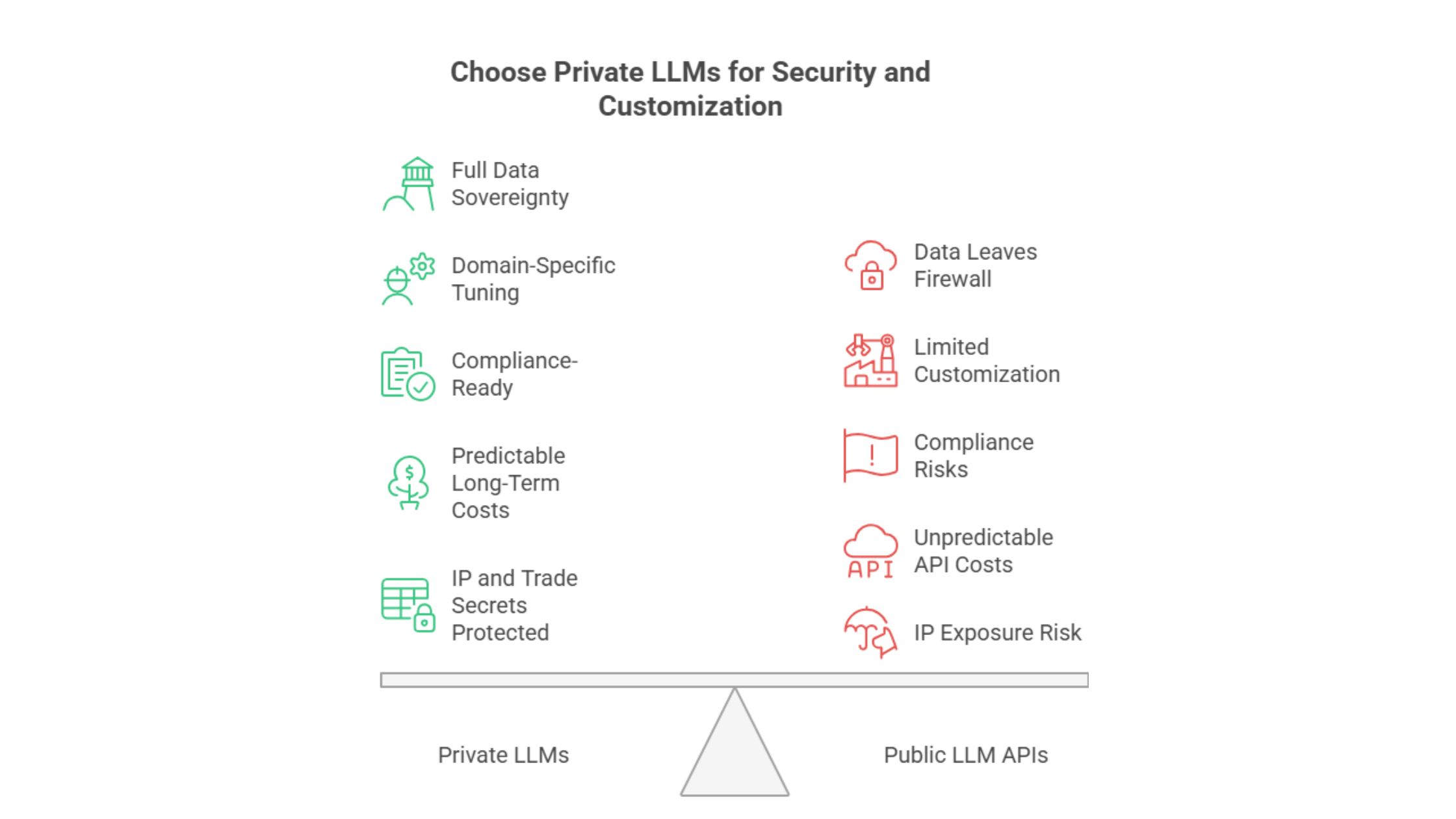
Choosing where to host private LLMs is a strategic decision. Both on-premise and private cloud architectures can deliver secure environments, but they differ in trade-offs around control, scalability, and operational burden.
On-Premise (Air-gapped or Enterprise Data Center)
- Pros: Maximum control, strict data residency, full isolation, direct integration with legacy systems.
- Cons: High CapEx, longer procurement cycles, in-house expertise required for operations and scaling.
Private Cloud (Dedicated VPC or Hosted Private Cloud)
- Pros: Faster provisioning, elastic capacity, vendor-managed maintenance, easier geographic distribution.
- Cons: Relies on vendor compliance, potentially higher OpEx over time.
Hybrid Model
Many enterprises choose hybrid: on-prem for highly sensitive workloads and private cloud for development, non-sensitive inference, or burst capacity.
Comparison Table
| Factor | On-Premise | Private Cloud |
| Data sovereignty | Highest — stays in org boundary | High — depends on provider & contracts |
| Scalability | Limited by in-house hardware | Elastic GPU scaling |
| Deployment speed | Slower (procure & setup) | Faster (provision through vendor) |
| Operational overhead | High (IT & infra teams) | Lower (vendor-managed ops) |
| Cost model | CapEx heavy, predictable long-term | OpEx (subscription/consumption) |
| Ideal for | Defense, critical banking workloads | Pharma R&D, cross-border teams, pilot stages |
(Internal reference: potential of custom LLM — used once.)
Industry Use Cases of Private LLMs Development
Private LLMs enable specialized, high-value use cases across sectors. Below are detailed examples illustrating why on-prem or private LLMs are preferred.
Healthcare
- Clinical documentation automation: Private LLMs transcribe and summarize consultations, populate EHR fields, and generate clinical notes while ensuring HIPAA-grade privacy.
- Decision support & knowledge retrieval: Provide clinicians with relevant literature and patient-history-aware suggestions without exposing patient data externally.
Banking & Financial Services (BFSI)
- Secure advisory assistants: Agent that accesses internal account data, product catalogs, and compliance rules to make personalized recommendations.
- Real-time fraud detection augmentation: LLMs analyze natural language case notes and customer chat transcripts to detect and escalate suspicious activity.
Pharmaceuticals & Life Sciences
- Research summarization: Private LLMs index internal trial reports and published literature to accelerate discovery.
- Regulatory filing support: Generate draft filings and summarize trial results while keeping IP and trial participant data on-prem.
Manufacturing & Industrial IoT
- Predictive maintenance: Integrate sensor logs and maintenance reports to produce work orders and diagnostic suggestions.
- Process optimization: Use proprietary process rules and historical failures to create prescriptive actions.
Defense & Aerospace
- Secure intelligence analysis: Aggregate reports, sensor feeds, and tactical logs; produce distilled intelligence products in air-gapped environments.
- Mission planning assistance: Support scenario simulations while maintaining national security controls.
Legal & Professional Services
- Contract review & summarization: Fine-tuned models trained on internal contracts provide risk flags, clause extraction, and precedent search.
- Knowledge management: Firm-specific legal knowledge bases power internal search and drafting aides.
Retail & Supply Chain
- Demand forecasting augmentation: Combine internal promotions, supplier notes, and historical chatter to refine forecasts.
- Secure supplier negotiation assistants: Confidentiality is preserved when generating negotiation playbooks and scenario responses.
Each use case shares a common theme: the combination of domain-specific knowledge + data sensitivity drives the need for private LLMs.
The Role of Customization & Fine-Tuning
Customization is the differentiator between a generic model and an enterprise-grade private LLM. Fine-tuning and prompt engineering make the model relevant to internal workflows.
Why fine-tune?
- Domain terminology: Teach the model company-specific terminology, acronyms, and contextual signals.
- Policy alignment: Embed tone, compliance constraints, and response style.
- Performance gains: Reduce hallucinations and increase answer precision for internal tasks.
Techniques
- Full fine-tuning: Retraining model weights on labeled corpora for highest fidelity (resource intensive).
- Parameter-efficient tuning (LoRA, adapters): Lower resource usage while achieving good performance for many tasks.
- Hybrid RAG + fine-tuning: Use retrieval systems for up-to-date facts and fine-tune for style and domain behavior.
- Prompt tuning & instruction tuning: Improve response behavior with curated instruction datasets.
Operational concerns
- Maintain training data hygiene (no PII leaks); keep immutable checkpoints and version metadata; store training recipes in the model registry. Use chunking strategies to build retrieval corpora that maximize context relevance for RAG workflows. (Internal reference: chunking strategy for LLM applications — used once.)
Customization is a continuous activity: as new data arrives, fine-tuning cycles and retrieval index updates keep the model aligned with enterprise knowledge.
Comparing Private LLMs with Public LLM APIs
Understanding the trade-offs helps build the right deployment strategy.
Security & Compliance
- Private LLMs: Data remains inside controlled boundaries — stronger for regulated tasks.
- Public APIs: Easier to implement but expose prompts and responses to third parties (risk for sensitive data).
Customization
- Private: Full control to fine-tune and adapt models.
- Public: Limited fine-tuning; some vendors offer fine-tuning but data handling terms vary.
Cost
- Private: High initial CapEx and operational costs but predictable at scale.
- Public: Low initial cost; recurring expense can grow with usage.
Speed to Market
- Public APIs: Fastest for prototyping.
- Private: Slower upfront but more robust for production, compliance, and scale for sensitive workloads.
Ecosystem & Ops
- Private: Requires MLOps and infrastructure teams.
- Public: Vendor-managed ops relieve internal teams.
Choice is often hybrid: prototype with public APIs, then transition sensitive and production workloads to private LLMs.
Small vs Large LLMs in Private Deployments
Not all enterprise problems require the largest models. Choosing the right model size impacts cost, latency, and feasibility.
Small LLMs (efficient models)
- Pros: Lower inference cost, can run on fewer GPUs, faster latency, easier to deploy at edge and on-prem appliances.
- Use cases: Domain-specific assistants, edge devices, high-throughput conversational logging, automation for structured tasks.
Large LLMs (high-parameter models)
- Pros: Better generalization, deeper contextual reasoning, stronger zero-shot and few-shot capabilities.
- Cons: Higher hardware requirements, greater latency, more expensive training & inference.
Strategy
We often recommend a tiered approach:
- Use small or mid-sized private models for routine, high-volume tasks.
- Reserve larger models for complex reasoning or when accuracy gains justify cost.
- Use model distillation or quantization to compress large-model capabilities into more efficient deployments.
To learn about model families and enterprise offerings, see our overview of enterprise-grade large language models. (Internal reference: Large Language Models — used once.)
Open-Source Models vs Custom-Built Private LLMs
Enterprises can base private LLM development on open-source foundations or build on licensed/partner models. Each approach has trade-offs.
Open-Source Foundations
- Advantages: Cost-effective starting point, community innovation, full code & model access, easier to avoid vendor lock-in.
- Challenges: Operational burden for reliability, need for security hardening, potential licensing restrictions.
Commercial/Licensed Models
- Advantages: Enterprise support, optimized performance, compliance-ready variants, and managed updates.
- Challenges: Higher licensing costs, some limits on model modification, potential vendor lock-in.
Hybrid & Composition
A common pattern is open-source base + enterprise layers:
- Start with an open-source base for flexibility and cost control.
- Add enterprise components: fine-tuning, safety filters, monitoring, and compliance wrappers.
- Where needed, use licensed models for critical features or where SLA-backed support matters.
Decision factors include: data sensitivity, in-house MLOps maturity, required support SLAs, and long-term vendor strategy.
Infrastructure Planning for Private LLMs Development
Robust infrastructure planning is essential to ensure reliability, performance, and total cost control.
Hardware & Compute
- GPU selection: Choose GPU types based on model size and throughput (e.g., NVIDIA A100/H100, alternatives where supported). Consider memory, NVLink, and PCIe bandwidth.
- Accelerators: Evaluate TPUs or other hardware if supported by your model stack.
- Storage: High-throughput, low-latency storage for datasets and checkpoints (NVMe, parallel file systems).
- Networking: Low-latency interconnects (InfiniBand) to scale distributed training.
Capacity & Sizing
- Forecast workloads: training cycles, fine-tuning runs, production inference QPS (queries per second).
- Plan for peak demand and burst capacity (e.g., orchestrate spare capacity or private cloud burst).
Energy & Facilities
- Power and cooling design, especially for on-prem clusters, affects running costs and sustainability. Consider co-location or managed private cloud if facilities constraints exist.
Software & Orchestration
- Use containerized stacks (Kubernetes) with orchestration for GPU scheduling (KubeFlow, Kubeflow Pipelines, or other MLOps platforms).
- Deploy model serving frameworks that support batching, quantization, and autoscaling.
Security & Isolation
- Network segmentation, HSMs for key management, and physical access controls for on-prem hardware. Implement secure boot and signed images.
Observability & Telemetry
- Monitor GPU utilization, latency, error rates, and drift. Implement dashboards and alerts for proactive ops.
Proper infrastructure planning aligns capacity to business demand and ensures predictable performance for mission-critical services.
Data Pipeline & Preprocessing for Private LLMs
Good model performance starts with disciplined data engineering. A private LLM program needs robust pipelines for collecting, preparing, and maintaining data.
Data Collection & Ingestion
- Identify authoritative internal sources: knowledge bases, documentation, contracts, logs, CRM transcripts.
- Ingest data with provenance: capture source, timestamp, and ownership metadata.
Cleaning & Normalization
- Remove PII where not required or apply redaction/anonymization techniques.
- Normalize formats, remove duplicates, and filter low-quality content.
Chunking & Context Windowing
- Break long documents into meaningful chunks while preserving context. Use semantic chunk sizes tuned for your model’s context window. Chunking improves retrieval precision in RAG systems.
Embedding Generation & Indexing
- Generate embeddings for chunks and index them in a vector DB with metadata tags to support efficient retrieval and access control.
Data Versioning & Lineage
- Use dataset versioning to track changes and enable reproducible training. Store hash-based manifests for datasets used in each training run.
Synthetic Data & Augmentation
- Where data is scarce, carefully create synthetic examples or augmentation strategies while validating for bias and distribution shifts.
Continuous Data Refresh
- Set processes to ingest and re-index new documents routinely so the model reflects current policy, product, and knowledge.
A production-ready data pipeline ensures model relevance, reduces hallucinations, and aligns outputs with enterprise knowledge.
AI Governance and Risk Management in Private LLMs
Governance must be operational, not just theoretical. We recommend concrete frameworks and tooling to manage risk.
Governance Layers
- Strategic: Policies, risk appetite, and AI ethics principles set by leadership.
- Operational: Processes for model approval, testing, and deployment.
- Technical: Controls embedded in code — input/output filtering, rate limits, and policy enforcers.
Risk Management Practices
- Risk classification: Categorize models by risk level (e.g., low, medium, high) and apply controls accordingly.
- Safety testing: Evaluate models for bias, fairness, and harmful outputs using standardized test suites.
- Explainability & provenance: Maintain model cards, data sheets, and decision provenance for audits.
Monitoring & Incident Response
- Implement real-time monitoring for anomalies, drift, and policy infractions.
- Define incident playbooks for model behavior that violates policies (e.g., leakage of PII or sensitive content).
Compliance & Audit
- Preserve logs, immutably store evidence required for regulatory audits, and provide reproducible training records.
Organizational Setup
- Establish a cross-functional AI governance council with legal, compliance, security, data science, and product representatives to approve high-risk use cases and maintain oversight.
Operational governance reduces legal exposure and speeds time-to-production for safe, auditable LLM initiatives.
Integration of Private LLMs with Enterprise Systems
Private LLMs deliver value only when integrated with business processes and systems.
Typical integration targets
- CRM systems: Enhance sales and support agents with context-rich summaries and suggested responses.
- ERP & supply chain systems: Provide natural-language querying and explanation of KPIs and orders.
- Service desks: Automate ticket triage, resolution suggestions, and knowledge base linking.
- BI tools & dashboards: Generate natural language insights from analytics datasets.
Integration patterns
- Microservice APIs: Expose secure inference endpoints with authentication, rate limits, and observability.
- Event-driven triggers: Use message queues and events to process documents for indexing and model updates.
- Middleware & connectors: Use adapters to integrate with legacy systems that don’t support modern APIs.
Security considerations
- Ensure strict authentication (mTLS, OAuth), request filtering, and input sanitization. Implement per-call audit logging to link model outputs back to user actions.
Seamless integration accelerates adoption and drives measurable business impact.
Cost Analysis: Private LLMs vs Public APIs
When evaluating private LLMs, organizations should consider both total cost of ownership (TCO) and strategic value. Key cost factors:
Upfront & Capital Costs
- Hardware procurement: GPUs, servers, storage, networking.
- Facility costs: Power, cooling, rack space, or co-location fees.
- Software & licensing: MLOps tooling, model licensing (if applicable).
Operating Costs
- Personnel: MLOps engineers, DevOps, security, and data scientists.
- Maintenance & upgrades: Patch cycles and hardware refreshes.
- Energy & facility overhead.
Variable Costs
- Training cycles: Large fine-tuning runs can be compute intensive.
- Inference scale: High QPS workloads increase GPU utilization and cost.
Public API Model Costs
- Pay-per-use pricing avoids CapEx but can become expensive at scale or with high fine-tuning volumes. Latency and data egress costs may also apply.
Economic Trade-offs
- For heavy, predictable usage, private deployments often achieve lower TCO over a 2–4 year horizon due to amortized hardware and shared infra across projects. For small pilots or unpredictable workloads, public APIs reduce initial investment.
According to Gartner research, organizations that transition core AI workloads to private or hybrid deployments frequently report lower long-term costs and improved governance outcomes, provided they can operationalize MLOps and sustain infrastructure investments. (External source: Gartner — used once.)
A complete cost analysis should model expected training runs, inference QPS, staff costs, and regulatory compliance costs to compare scenarios.
Challenges in Private LLMs Development
Private LLM programs face practical challenges. Understanding them upfront enables better planning.
1. Hardware scarcity & procurement cycles
High-end GPUs can be scarce and procurement lead times long. Mitigation: plan capacity ahead, leverage managed private cloud bursting, or use alternate hardware.
2. Talent & skills gap
MLOps, distributed training, and secure deployment require specialized talent. Mitigation: invest in training, partner with experienced vendors, or adopt managed services.
3. Model maintenance & lifecycle
Models degrade over time due to drift and stale knowledge. Implement monitoring, scheduled re-training, and governance for updates.
4. Integration complexity
Legacy systems present integration friction. Mitigation: create connectors and middleware layers to standardize integration patterns.
5. Cost predictability
Without careful capacity planning, costs can overrun. Build proper budgeting, tagging, and chargeback mechanisms.
6. Vendor lock-in & interoperability
Relying on proprietary stacks increases lock-in risk. Favor modular architectures and open standards where possible.
7. Safety & hallucination risk
Even private LLMs hallucinate. Use RAG, human-in-the-loop, and strong evaluation metrics to reduce harmful outputs.
By acknowledging these challenges, we can design risk-mitigated roadmaps that de-risk adoption and deliver value.
Best Practices for Enterprises Building Private LLMs
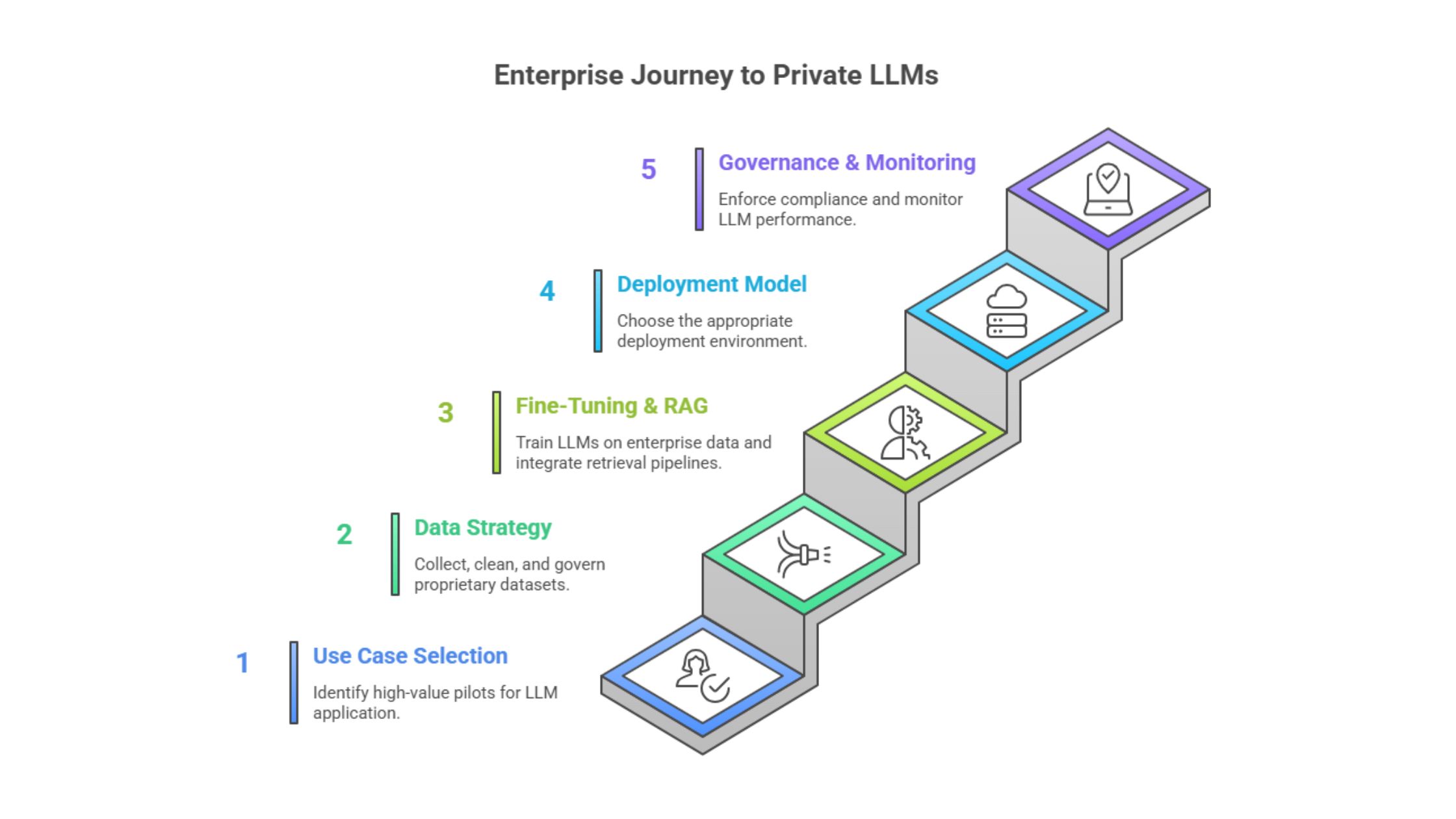
We recommend a governance-first, iterative approach. Below are proven best practices we follow when delivering private LLM programs.
1. Start with high-value pilots
Choose use cases with clear success metrics (time saved, error reduction, NPS improvement). Pilot in a contained environment to validate ROI.
2. Adopt a hybrid rollout plan
Pilot on private cloud for speed, then graduate to on-premise for sensitive production workloads. This enables rapid learning without sacrificing compliance.
3. Build an MLOps foundation
Invest in CI/CD for models, automated tests for safety and bias, model registries, and reproducible training pipelines.
4. Implement data hygiene & lineage
Treat data like a first-class product. Version datasets, capture provenance, and apply quality gates before training.
5. Enforce governance & approvals
Use a risk classification framework and require governance approvals for high-risk use cases. Automate policy enforcement where possible.
6. Optimize for cost & efficiency
Leverage parameter-efficient tuning (LoRA), quantization, and distillation to reduce resource consumption. Reuse infrastructure across projects.
7. Design for observability
Monitor key indicators: latency, error rates, drift metrics, user satisfaction, and anomalous outputs. Feed monitoring into incident workflows.
8. Invest in cross-functional teams
Pair data scientists with security, legal, and product managers to accelerate approvals and maintain compliance without slowing delivery.
9. Plan for model lifecycle
Define schedules for retraining, model retirement, and post-deployment reviews.
10. Partner where it makes sense
If in-house capability is immature, partner with vendors or system integrators to jumpstart the program — while focusing on retaining strategic control over data and models.
Following these practices shortens time to value and reduces operational risk.
Future Trends in Private LLMs Development
Several trends will shape private LLM programs over the next 3–5 years:
1. Multi-modal private models
Text, vision, audio, and structured data models integrated into single enterprise assistants will enable richer workflows (e.g., visual inspection plus textual analysis).
2. Efficient & smaller LLMs
Research into quantization, pruning, and distillation will produce compact models that run efficiently on enterprise GPUs or edge devices.
3. Standardized governance tooling
We’ll see more off-the-shelf tooling for model governance, auditing, and compliance that enterprises can plug into.
4. Federated & privacy-enhancing learning
Federated learning and secure aggregation techniques will allow collaboration across parties without sharing raw data.
5. Cloud–on-prem symbiosis
Hybrid orchestration will become mainstream: on-prem for controlled workloads and expendable cloud capacity for peaks.
6. Rising infrastructure share
Market forecasts indicate robust growth in AI system spending, with infrastructure and compliance-ready solutions capturing significant spend. For example, market research projects continued growth in global AI system spending over the coming decade. (External source: Statista — used once.)
These trends point to a maturing market where private LLMs become not only feasible but strategically central for regulated and IP-sensitive enterprises.
Why Choose AIVeda for Private LLMs Development
Building private LLMs is as much about execution and trust as it is about models. Here’s why partnering with a provider like AIVeda accelerates outcomes:
1. Domain-focused expertise
We specialize in regulated industries — healthcare, BFSI, pharma, manufacturing, and defense — and understand the compliance guardrails and procurement requirements that govern these sectors.
2. End-to-end delivery
From model selection and fine-tuning to secure on-prem or private cloud deployment, our team covers data engineering, MLOps, security hardening, and production integration.
3. Governance-first approach
We operationalize governance through auditable pipelines, policy engines, and monitoring so enterprises meet auditors’ expectations without blocking innovation.
4. Cost-optimized architectures
We help organizations choose the right mix of CapEx vs OpEx, hybrid bursting strategies, and parameter-efficient tuning techniques to reduce total cost of ownership.
5. Proven delivery and support
Our delivery methodology includes pilot-to-scale roadmaps, knowledge transfer, runbooks, and managed support to ensure continuity and ROI.
6. Focus on business outcomes
We align technical work to tangible KPIs: reduction in manual effort, improved resolution times, increased NPS, or reduced compliance exceptions.
If you’re planning a private LLM initiative, we can partner to design the architecture, de-risk the program, and help you deliver secure, value-driving AI inside your firewall.
Conclusion & Next Steps
Private LLMs development is a strategic enabler for enterprises that need to harness generative AI without exposing sensitive assets. By combining thoughtful model selection, robust data engineering, hardened infrastructure, and operational governance, organizations can unlock the productivity and innovation benefits of LLMs while meeting compliance and security requirements.
Next steps we recommend:
- Identify 2–3 high-impact pilot use cases with clear metrics.
- Assess readiness (infra, data quality, talent) and map spend/CapEx.
- Choose a deployment pattern (on-prem, private cloud, or hybrid) based on regulatory and scale needs.
- Run a time-boxed pilot to validate the model, integration, and costs.
- Establish governance and an AI council to approve scale decisions.
If you want to explore a pilot or need help assessing readiness, discover how AIVeda can help you design, build, and operate private LLMs for secure enterprise outcomes. Visit our Large Language Models page to learn more and request a discovery call. (Internal reference: AIVeda’s Large Language Models — used once.)
FAQs for Private LLMs Development: The Complete Guide
1. What is Private LLMs Development?
Private LLMs development refers to building and deploying large language models within enterprise-controlled environments (on-premise or private cloud). Unlike public APIs, data never leaves the firewall, ensuring security, compliance, and customization.
2. Why should enterprises choose private LLMs over public APIs?
Enterprises in regulated industries (like BFSI, healthcare, pharma, and defense) need strict compliance, data privacy, and IP protection. Private LLMs provide complete control, predictable costs, and domain-specific fine-tuning.
3. What infrastructure is required for private LLMs?
Private LLMs demand GPU/accelerator clusters, high-throughput storage, low-latency networking, and orchestration software (e.g., Kubernetes, MLOps stacks). Enterprises must also plan for cooling, redundancy, and monitoring.
4. Can private LLMs be deployed in hybrid models?
Yes. Many enterprises adopt hybrid strategies, keeping sensitive workloads on-prem while leveraging private cloud elasticity for less sensitive processes or peak demand.
5. How do private LLMs ensure compliance?
They allow enterprises to enforce governance policies, track data lineage, implement access controls, and ensure data never crosses jurisdictional or regulatory boundaries.
6. What are common challenges in private LLMs development?
Challenges include GPU shortages, high upfront costs, talent gaps, integration complexity, and continuous retraining needs. These can be mitigated through pilots, hybrid models, and strong MLOps practices.
7. What industries benefit most from private LLMs?
Industries like healthcare, BFSI, pharma, defense, and manufacturing — where data confidentiality, compliance, and proprietary knowledge are critical.
8. How much does private LLM development cost?
Costs vary by deployment (on-prem vs cloud), model size, and workloads. While CapEx is higher upfront, Gartner reports long-term cost efficiency compared to public API dependence.
{
“@context”: “https://schema.org”,
“@type”: “FAQPage”,
“mainEntity”: [
{
“@type”: “Question”,
“name”: “What is Private LLMs Development?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Private LLMs development refers to building and deploying large language models within enterprise-controlled environments such as on-premise or private cloud. Unlike public APIs, data never leaves the firewall, ensuring security, compliance, and customization.”
}
},
{
“@type”: “Question”,
“name”: “Why should enterprises choose private LLMs over public APIs?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Enterprises in regulated industries like BFSI, healthcare, pharma, and defense require strict compliance, data privacy, and IP protection. Private LLMs provide complete control, predictable costs, and domain-specific fine-tuning, unlike public APIs.”
}
},
{
“@type”: “Question”,
“name”: “What infrastructure is required for private LLMs?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Private LLMs demand GPU/accelerator clusters, high-throughput storage, low-latency networking, and orchestration software such as Kubernetes or MLOps stacks. Enterprises must also plan for cooling, redundancy, and monitoring.”
}
},
{
“@type”: “Question”,
“name”: “Can private LLMs be deployed in hybrid models?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Yes. Many enterprises adopt hybrid strategies, keeping sensitive workloads on-prem while leveraging private cloud elasticity for less sensitive processes or peak demand.”
}
},
{
“@type”: “Question”,
“name”: “How do private LLMs ensure compliance?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “They enforce governance policies, track data lineage, implement access controls, and ensure that data never crosses jurisdictional or regulatory boundaries, aligning with HIPAA, GDPR, RBI/SEBI, and other frameworks.”
}
},
{
“@type”: “Question”,
“name”: “What are common challenges in private LLMs development?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Challenges include GPU shortages, high upfront costs, talent gaps, integration complexity, and continuous retraining needs. These can be mitigated through pilot projects, hybrid models, and strong MLOps practices.”
}
},
{
“@type”: “Question”,
“name”: “What industries benefit most from private LLMs?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Industries such as healthcare, BFSI, pharma, defense, and manufacturing, where data confidentiality, compliance, and proprietary knowledge are critical, benefit the most from private LLMs.”
}
},
{
“@type”: “Question”,
“name”: “How much does private LLM development cost?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Costs vary depending on deployment model (on-prem vs cloud), model size, and workloads. While CapEx is higher upfront, Gartner reports that private LLMs often deliver long-term cost efficiency compared to recurring public API usage.”
}
}
]
}
7 Comments
[…] Private LLMs bring AI innovation inside the walls of your organization—where your data stays encrypted, your IP remains protected, and your AI outputs reflect your company’s unique operational context. This shift has made private LLM use cases the preferred path for enterprises that view data not as an asset to be shared, but as a competitive moat to be guarded. […]
[…] of every centralized AI system lies trust, and trust begins with control. That’s why AIVeda’s Private LLM (Large Language Model) forms the secure core of the AI nervous system architecture, ensuring that enterprise intelligence […]
[…] https://aiveda.io/blog/private-llms-development-the-complete-guide […]
[…] Private LLMs give enterprises something public models cannot—control. Full control over data. Full control over model behavior. Full control over how intelligence flows inside the business. A private LLM becomes part of the enterprise’s secure architecture. […]
[…] is where private LLM deployment becomes essential. However, deploying a private LLM securely is far from simple. It requires […]
[…] For complete guidance on private LLM, check out Private LLMs Development: The Complete Guide […]
[…] bring hands-on experience in model compression, private LLM deployment, and enterprise-grade integrations. That means faster rollouts, lower overhead, and models that […]